AI assisted code reviews
Using AI to review your pull-requests
I recently came across the concept of using AI to review pull-requests. I thought this was a brilliant idea and decided to try it myself. It turns out there are already services tightly integrated with GitHub/GitBucket that can handle this, as well as some GitHub Actions. However, there’s still room for improvement, and some may prefer a custom solution tailored to their needs. Additionally, keeping code private and avoiding third-party services is a valid concern.
I decided to experiment with a custom solution using Google’s Gemini model and a self-hosted GitHub server to run workflows with hardware-in-the-loop (HIL). Note that this is a proof of concept rather than a production-ready solution. Toward the end, I’ll discuss potential improvements to the workflow. For now, let’s build something that works.
Requirements
- STM32 Nucleo-H723 running FreeRTOS
- Self-hosted Github server
- Access to some kind AI model API (Gemini, GPT-4, etc.)
- You need to make a repository secret with the name
NONYA_BUSINESS_API_KEYand the value of your API key. It can be any name you want, but you will need to update the code accordingly.
Setting the github workflow
I won’t detail how to set up a self-hosted GitHub server, as it’s straightforward and I’ll assume you have one running.
The workflow needs to accomplish the following:
- Check out the code
- Build the code
- Flash the hardware
- Provide AI with a diff of the code (meaning the changes made in the pull-request)
- Push that diff to the AI model and get a response
- Post the response as a comment on the pull-request
Build and flash the device
For this proof of concept, flashing the device isn’t strictly necessary since the focus is on AI code reviews.
However, I’ll include it in the workflow to meet the HIL requirement.
First order of business is to set up the workflow. The workflow YAML file should be placed in .github/workflows/ and should look something like this:
name: Flash Device
on:
pull_request:
branches:
- main
workflow_dispatch: # Allows manual triggering of the workflow
This snippet sets up a workflow that runs on pull requests to the main branch and supports manual triggering. Next, define the jobs.
The first job, flash, checks out the code, builds it, and flashes the device. For clarity, I’m breaking the YAML into sections, but it all belongs in a single file:
jobs:
flash:
runs-on: self-hosted
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.x'
- name: Create virtual environment
run: |
python -m venv .venv
source .venv/bin/activate
- name: Install dependencies
run: |
source .venv/bin/activate
python -m pip install --upgrade pip
pip install -r .github/workflows/helpers/requirements.txt
- name: Build firmware
run: |
cmake --preset=Debug
cmake --build --preset=Debug
- name: Flash the device
env:
PROJECT_DIR: ${{ github.workspace }}
run: |
source .venv/bin/activate
python .github/workflows/helpers/flash_device.py
The Build firmware step is specific to the STM32’s CMake setup, but you can replace it with your preferred build system.
The flash job runs on a self-hosted runner, which is necessary for HIL workflows unless you’re shipping hardware to GitHub (ha!). Each step in a job is a command that will be run in the order they are defined.
Checkout repositorywill check out the code in the pull-request.Set up Pythonwill set up a python environment for us to use.Create virtual environmentwill create a virtual environment for us to use.Install dependencieswill install the dependencies in the requirements.txt file.Build firmwarewill build the firmware using cmake.Flash the devicewill flash the device using a python script that I will provide later.
It is important to note that Python is used here because I chose it for the flash script. Alternatively, you could use a Bash script and install ARM GNU binaries and OpenOCD on the self-hosted runner. Since the runner is an isolated environment, it lacks default tools. My script uses a direct path to STM32CubeProgrammer, but ideally, you’d install tools in the runner’s directory.
The env section in the Flash the device step is used to set environment variables that will be available to the python script. Also note the sourcing
of the virtual environment in every step, since every step can be thought of as a separate shell, we need to source the virtual environment in every step that needs it.
The python script will look like this:
import subprocess
import os
def flash_device():
# Get the project directory from the environment variable
project_dir = os.getenv("PROJECT_DIR", "")
if not project_dir:
raise ValueError("PROJECT_DIR environment variable is not set.")
elf_file = os.path.join(project_dir, "build/Debug/CICD-HIL-AI.elf")
if not os.path.isfile(elf_file):
raise FileNotFoundError(f"ELF file not found: {elf_file}")
# Define the command to flash the device
command = [
"/home/eddie/st/stm32cubeclt_1.17.0/STM32CubeProgrammer/bin/STM32_Programmer_CLI",
"-c", "port=SWD",
"-w", os.path.join(project_dir, "build/Debug/CICD-HIL-AI.elf"),
"-v",
"-rst",
"-run"
]
try:
# Run the command
result = subprocess.run(command, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print("Flashing successful:")
print(result.stdout.decode())
except subprocess.CalledProcessError as e:
print("Error during flashing:")
print(e.stderr.decode())
raise
if __name__ == "__main__":
flash_device()
Not too much going on here, first we do some error checking making that both the directory and file exist, then we are using the subprocess module to run the STM32CubeProgrammer CLI tool to flash the device.
The command args are as follows:
-coption to specify the connection type, in this case SWD.-woption to specify the file to flash.-voption to verify the flash.-rstoption is used to reset the device after flashing-runoption is used to run the program after flashing.
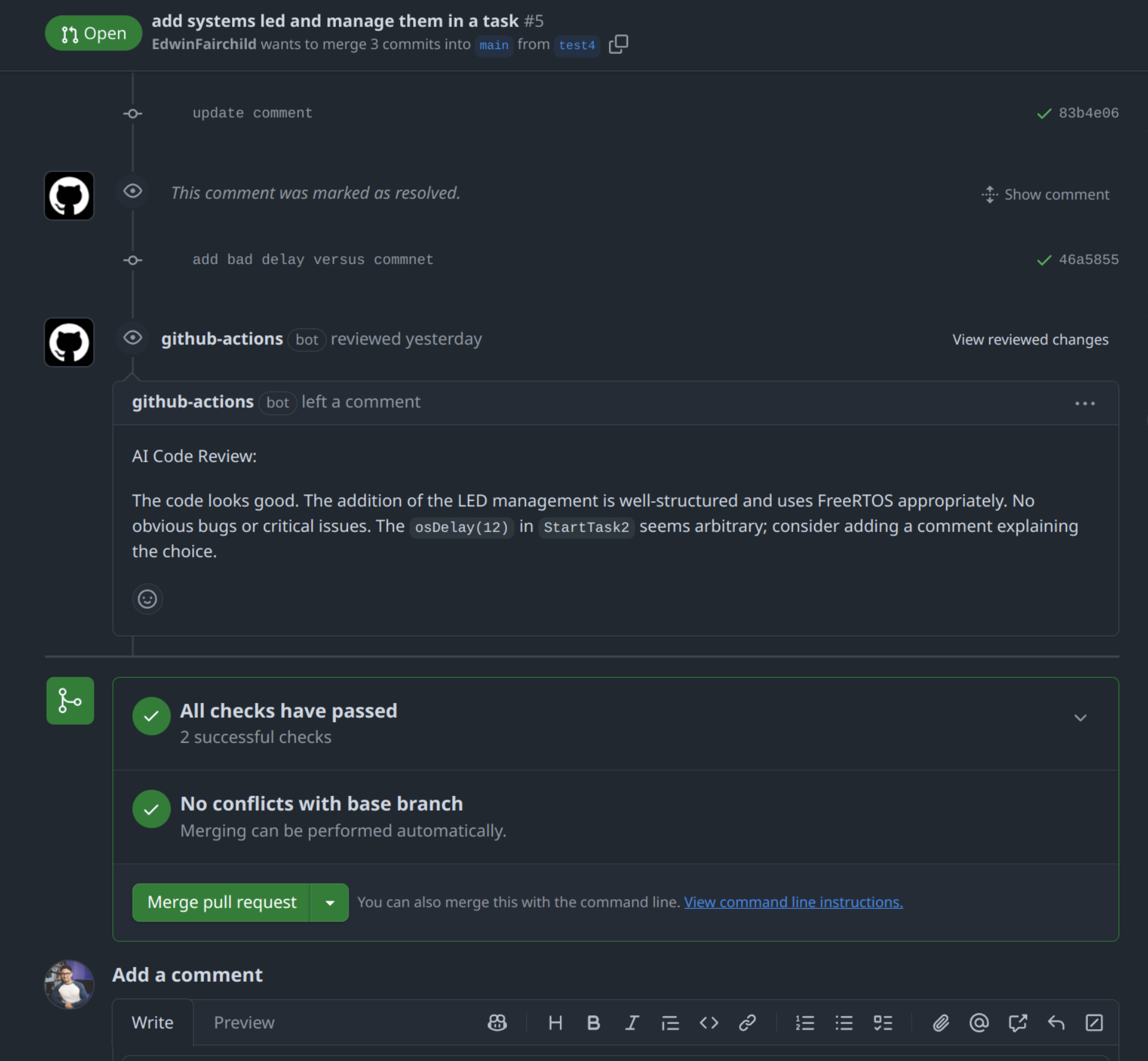
Get diff and AI code review
Now that we have the device flashed, we need to get the diff of the code and send it to the AI model. Thankfully github makes its pretty easy to get all the things we need. The AI code review job looks like this:
ai_code_review:
runs-on: ubuntu-latest
if: github.event_name == 'pull_request' && !contains(github.event.pull_request.title, '@NOAI')
permissions:
contents: read
pull-requests: write
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.x'
- name: Create virtual environment
run: |
python -m venv .venv
source .venv/bin/activate
- name: Install dependencies
run: |
source .venv/bin/activate
python -m pip install --upgrade pip
pip install -r .github/workflows/helpers/requirements.txt
- name: Get AI Code Review
env:
GEMINI_API_KEY_SECRET: ${{ secrets.NONYA_BUSINESS_API_KEY }}
PR_DIFF_URL: ${{ github.event.pull_request.diff_url }}
GITHUB_TOKEN_SECRET: ${{ secrets.GITHUB_TOKEN }}
GITHUB_REPOSITORY: ${{ github.repository }}
PR_NUMBER: ${{ github.event.pull_request.number }}
run: |
source .venv/bin/activate
python .github/workflows/helpers/ai_pr_reviewer.py
Lets break it down.
This time we are using ubuntu-latest as the runner since we do not need hardware in the loop for this job.
The job will only run if the event is a pull-request and the title does not contain @NOAI.
This allows us to skip the AI review if we want to by simply adding @NOAI to the title of the pull-request. Cool party trick for sure.
The permissions section is important, we need to give the job permission to read the contents of the repository and write to the pull-request.
Most of the steps are similar to the previous as far as checking out the code and setting up the python environment.
The only difference is the Get AI Code Review step, which will run a python script that will get the diff of the code and send it to the AI model.
In the env section we are setting up some environment variables that will be used in the python script.
GEMINI_API_KEY_SECRETis the API key for the AI model, in this case Gemini, I am using github methods to get the secret.PR_DIFF_URLis the url for the diff of the pull-request, this is provided by github and is used to get the changes made in the pull-request.GITHUB_TOKEN_SECRETis the token for the github API, this is also provided by github and is used to post comments on the pull-request.GITHUB_REPOSITORYis the name of the repository, this is provided by github and is used to post comments on the pull-request.PR_NUMBERis the number of the pull-request, this is provided by github and is used to post comments on the pull-request.
All of these variables will be made available to the environment and can be sourced in the python script. The python script will look like this:
# .github/workflows/helpers/ai_pr_reviewer.py
import os
import requests
import google.generativeai as genai
import sys
# Configuration
# Max characters of the diff to send to Gemini. Adjust if needed based on token limits and typical PR size.
# gemini-pro has a 32k token limit (input). ~4 chars/token. 25000 chars ~ 6250 tokens.
MAX_DIFF_CHARS = 25000
GEMINI_MODEL = "gemini-1.5-flash-latest" # Use flash for speed and cost-effectiveness for this task
def fetch_pr_diff(diff_url, github_token):
"""Fetches the diff content of a PR."""
headers = {
"Authorization": f"Bearer {github_token}", # Use Bearer for GITHUB_TOKEN
"Accept": "application/vnd.github.v3.diff",
}
try:
response = requests.get(diff_url, headers=headers, timeout=30)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
print(f"::error::Failed to fetch PR diff from {diff_url}: {e}", file=sys.stderr)
return None
def get_ai_review(api_key: str, diff_content: str) -> str:
"""Gets a code review from Google Gemini."""
if not diff_content or not diff_content.strip():
print("::info::No diff content to review.", file=sys.stderr)
return "NO_REVIEW"
if len(diff_content) > MAX_DIFF_CHARS:
warning_msg = (
f"Diff content is large ({len(diff_content)} chars). "
f"Truncating to {MAX_DIFF_CHARS} chars for AI review. Full context may be lost."
)
print(f"::warning::{warning_msg}", file=sys.stderr)
diff_content = (
diff_content[:MAX_DIFF_CHARS] + "\n\n... (diff truncated due to length)"
)
genai.configure(api_key=api_key)
model = genai.GenerativeModel(GEMINI_MODEL)
prompt = (
"You are an expert code reviewer for embedded systems.\n"
"You are reviewing a Pull Request. The following is a unified diff of the changes.\n"
"Your task is to:\n"
"1. Identify potential bugs, logical errors, or anti-patterns.\n"
"2. Check for violations of embedded C/C++ best practices (e.g., resource management, "
"volatile correctness, interrupt safety if inferable).\n"
"3. Look for areas where code could be optimized for performance or clarity.\n"
"4. Provide constructive feedback and suggested improvements only if absolutely necessary, be concise\n"
"5. If everything looks good, say so clearly.\n\n"
"6. No one wants to read a novel, so keep it short and concise. Tokens cost money!!!\n\n"
"Here is the diff:\n"
f"{diff_content}"
)
try:
response = model.generate_content(prompt)
return response.text.strip()
except Exception as e:
print(f"::error::AI review failed: {e}", file=sys.stderr)
return "AI_REVIEW_FAILED"
def post_pr_review(github_token: str, repo: str, pr_number: str, comment: str):
"""Posts a review comment to the specified PR using the GitHub API."""
url = f"https://api.github.com/repos/{repo}/pulls/{pr_number}/reviews"
headers = {
"Authorization": f"Bearer {github_token}",
"Accept": "application/vnd.github.v3+json",
}
data = {
"body": comment,
"event": "COMMENT", # General comment without approving/rejecting
}
try:
response = requests.post(url, json=data, headers=headers, timeout=30)
response.raise_for_status()
print(f"::info::Successfully posted review comment to PR #{pr_number}")
except requests.exceptions.RequestException as e:
print(
f"::error::Failed to post review comment to PR #{pr_number}: {e}",
file=sys.stderr,
)
sys.exit(1)
if __name__ == "__main__":
# First, try environment variables (GitHub Actions mode)
gemini_api_key = os.getenv("GEMINI_API_KEY_SECRET")
pr_diff_url = os.getenv("PR_DIFF_URL")
github_token = os.getenv("GITHUB_TOKEN_SECRET")
repo = os.getenv("GITHUB_REPOSITORY")
pr_number = os.getenv("PR_NUMBER")
if gemini_api_key and pr_diff_url and github_token:
diff_text = fetch_pr_diff(pr_diff_url, github_token)
if diff_text is None:
print("NO_REVIEW")
sys.exit(0)
if not diff_text.strip():
print("::info::Diff is empty. No review needed.", file=sys.stderr)
print("NO_REVIEW")
sys.exit(0)
review_comment = get_ai_review(gemini_api_key, diff_text)
if review_comment == "NO_REVIEW":
comment = "AI Code Review: No review generated due to empty diff content."
elif review_comment == "AI_REVIEW_FAILED":
comment = "AI Code Review: Failed to generate review due to an error."
else:
comment = f"AI Code Review:\n\n{review_comment}"
# Post the review as a PR comment
post_pr_review(github_token, repo, pr_number, comment)
print(review_comment) # Still print for logs
else:
# Local CLI mode: python ai_pr_reviewer.py <API_KEY> <diff_file>
if len(sys.argv) != 3:
print(
"Usage: python ai_pr_reviewer.py <API_KEY> <diff_file>", file=sys.stderr
)
sys.exit(1)
gemini_api_key = sys.argv[1]
diff_file = sys.argv[2]
try:
with open(diff_file, "r", encoding="utf-8") as f:
diff_text = f.read()
except Exception as e:
print(f"::error::Failed to read diff file: {e}", file=sys.stderr)
sys.exit(1)
review_comment = get_ai_review(gemini_api_key, diff_text)
print("\n===== AI REVIEW =====\n")
print(review_comment)
I will not go into detail about the code since it is not terrible hard to understand. But the gist of it is that we are sourcing the environment variables we set in the workflow and using them to get the diff of the pull-request. We send that diff along with a prompt to the AI model and get a response. We then post that response as a comment on the pull-request using the github API. The AI model is configured to look for bugs, logical errors, and anti-patterns in the code etc. That prompy is very important and you can tweak it to your liking. It can be very verbose and start going off into the weeds telling you how much you suck and your dad doesnt like you because you cant code for the life of you. But you can always tone it down by telling it to be concise and not to write a novel.
Most AI models right now have a free tier that you can use to test it out, and if you go for the basic models you can get decent reviews for free.
Improvements
There are a lot of improvements that can be made to this workflow. For example:
- All steps should check for failure and exit the workflow if something goes wrong.
- Since this involves hardware in the loop, we should have a way to check if the hardware is connected and ready to be flashed.
- You should use lock files to prevent multiple pull-requests from trying to flash the hardware at the same time. The lock file should only be released by the process that made it.
- GitHub has a nice way to queue up jobs specially for cases like this, where you have multiple pull-requests and you want to run them in order and they must wait for their turn to not cause contention.
- Use the serial ID of the debugger you are using for the specific hardware that is to be flashed by the specific repo. This way you can have multiple hardware setups and they will not interfere with each other.
- Log your failed workflows and save artifacts for debugging.
- Consider giving AI more context about the project beyond the simple diff and prompt, giving it file tree, project type etc.
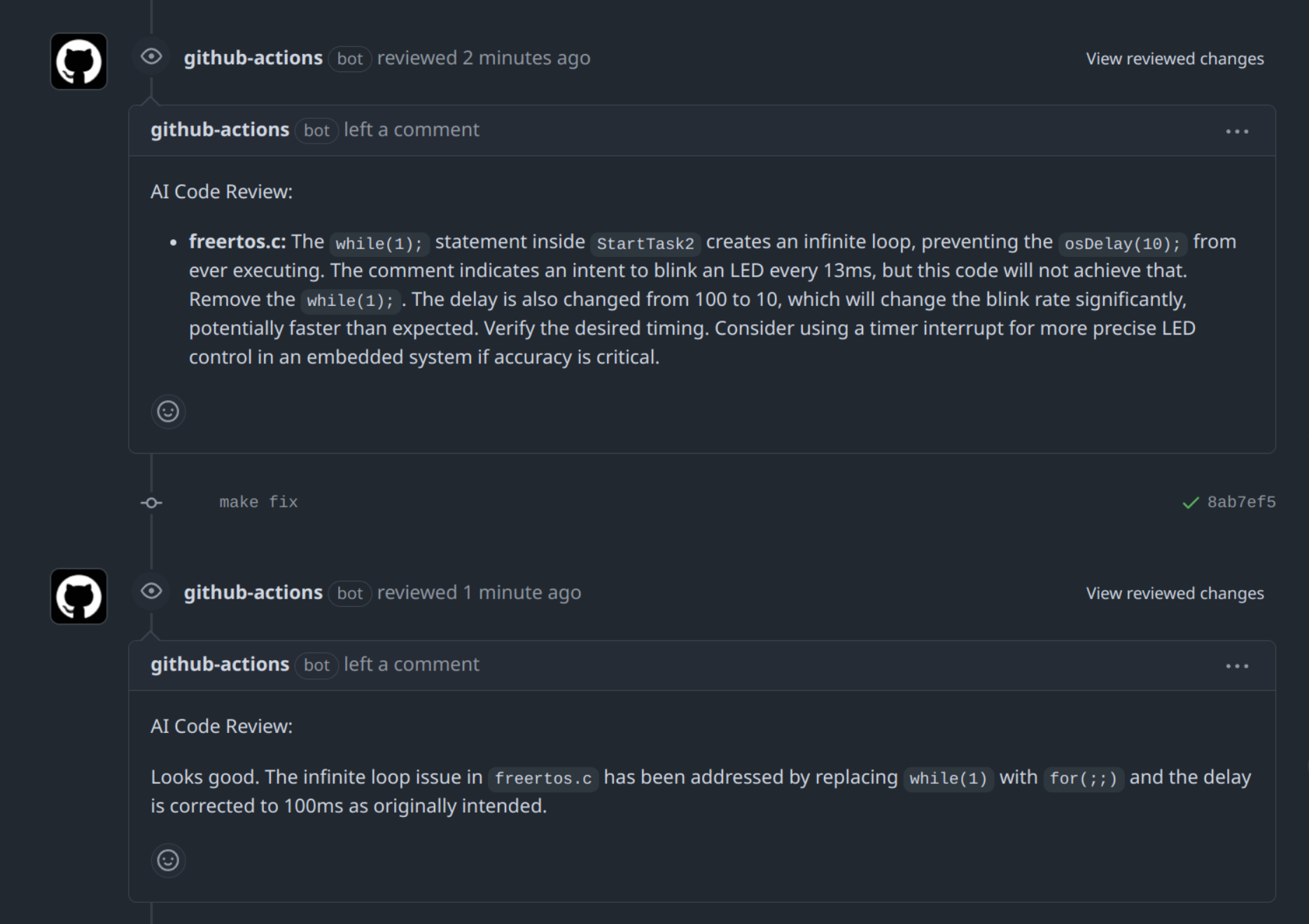
- (Update) I just added the ability for the ai reviewer to read its previous comments and use them as context for the review. This helps keep the conversational feel and allows the AI to remember what it said in the past.
Conclusion
Ultimately I dont think AI assited code reviews should be a blocker for merging pull-requests, but it can be a great tool to help you catch bugs and logical errors in your code. It is beneficial to both the developer and the reviewer.
You can find a link to the code on my GitHub and feel free to use it as a starting point for your own projects. I will be adding more features to this in the future, so stay tuned for updates.